RDBを取り巻くアレコレ(AWSを中心に)¶
データベース以前
- ファイルがデータストア
- 今もユニケージ開発手法はコレ
- [ユニケージ開発手法](ユニケージ開発手法)
データベース登場
- RDBの歴史~データ格納モデルの変遷~
-
データ重複の回避とシステム拡張の効率化のため、source fileにコンピュータ上の様々なデータを集約する
DBMS色々
- ネットワーク型DBMS
- 1964: 世界初の商用DBMS「IDS」はネットワーク型(GE製)
- 階層型DBMS
- メインフレーム用に生き残っている
- 1966: IMS(IBM製)
- [https://www.ibm.com/docs/ja/integration-bus/9.0.0?topic=ims-information-management-system](https://www.ibm.com/docs/ja/integration-bus/9.0.0?topic=ims-information-management-system)
- カード型DBMS
- FileMaker
- XML-DBMS
- ドキュメント指向DBのご先祖感...
- オブジェクト指向DBMS
- Smalltalk用に生きてるらしい
- [GemStone](https://gemtalksystems.com/products/gs64/)
RDB
- 関係(Relational)DB
- 1969: コッド氏が「A Relational Model of Data for Large Shared Data Banks」という有名な論文を発表
- Oracle
- 1979: 世界初の商用RDBMS
- MySQL
- PostgreSQL
- Amazon RDS
- Amazon Aurora
NoSQL("No SQL" -> "Not Only SQL")
- RDBでは耐えきれない読み込み・書き込みに耐えられるようにしたい
- 結果整合性、トランザクションレスを受け入れればスケーラブルにできる
- ACID特性 <-> BASE特性
- 結果整合性、トランザクションレスを受け入れればスケーラブルにできる
- 柔軟にスキーマを変更したい
- テーブル間の結合はできない代わりにスキーマレス
- 24時間365日の可用性を確保したい
- ドキュメント志向DB
- MongoDB
- LAMP -> MEAN(MongoDB + Express + AngularJS + Node.js)
- Amazon DocumentDB
- MongoDB
- KVS
- memcached
- Redis
- Apache Cassandra
- Amazon DynamoDB
- グラフ指向DB
- Amazon Neptune
- Neo4j
- 時系列DB
- Amazon Timestream
- 台帳DB
- Amazon QLDB
閑話休題: SQLっぽいクエリを投げられるPartiQL
- PartiQL: Amazon DynamoDB 用の SQL 互換クエリ言語
- DynamoDBや、JSONに対してSQLっぽいクエリを投げられる
- 表形式ではない、ネストのあるオブジェクトにもクエリできる
- DynamoDBや、JSONに対してSQLっぽいクエリを投げられる
- PartiQL AWSドキュメントじゃないサイトもある
ビッグデータ(最近聞かないねぇ...機械学習方面に食われたかな)
- RDBで扱うには大量のデータを実用的な時間で集計して分析したい
- Google File System + MapReduce -> HDFS + Apache Hadoop
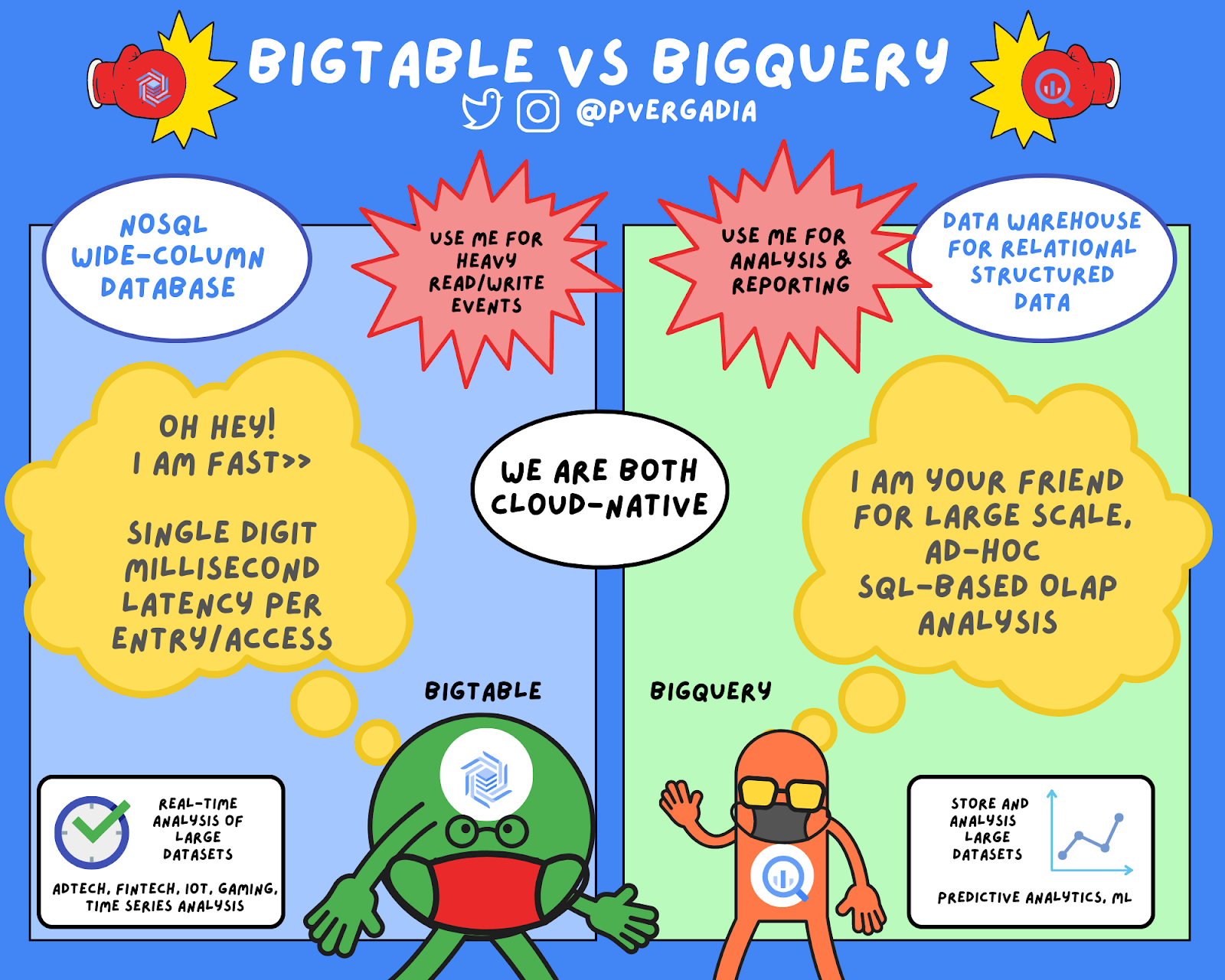
- 列ファミリーデータモデル: Google BigTable
-
Bigtable は、大量の読み取りと書き込み用に最適化された NoSQL ワイドカラム型データベースです。
-
- カラムナストレージ + treeアーキテクチャ: Google BigQuery
-
BigQuery は、大量のリレーショナル構造化データ用のエンタープライズ データ ウェアハウスです。
- https://cloud.google.com/blog/ja/topics/developers-practitioners/bigtable-vs-bigquery-whats-difference
- Amazon Redshift はカラムナストレージ
-
{kind=link}
NewSQL: 強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベース
- https://qiita.com/tzkoba/items/5316c6eac66510233115
- NoSQLへのクエリめんどくさい
- SQL使おう
- 結果整合性きつい
- 強い整合性がほしい
- トランザクションほしい
- 書き込みスケーラビリティがほしい
- マルチライター
- ストレージの自動拡張
- NoSQLへのクエリめんどくさい
- Google Cloud Spanner
- 2012: Spanner: Google's Globally-Distributed Database
- https://qiita.com/kumagi/items/7dbb0e2a76484f6c522b
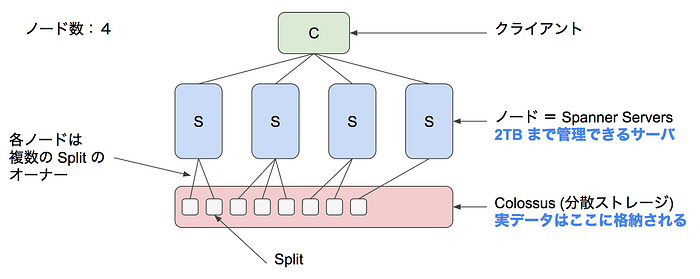
- 分散DBとしてのSpannerの裏側について
- 原子時計がなぜ必要か?
- そんなもんなくてもNTPで動くが
- 時刻が正確であるほど書き込みスループットが上げられる
- https://medium.com/google-cloud-jp/cloud-spanner-のハイレベルアーキテクチャ解説-fee62c17f7ed
- https://miro.medium.com/max/700/1*j55yeYVOBFq06aXvyFAZpA.png
- 1ノード起動するとリージョン内の各ゾーンにレプリカが起動する
- ゾーン間のレプリケーションはPaxosプロトコルで行われる
- マルチリージョンでの起動も可能
- Spanner Clone
- CockroachDB
- TiDB
- YugaByteDB
{kind=link}
閑話休題: Amazon AuroraはNewSQLか?
- [Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases](https://assets.amazon.science/dc/2b/4ef2b89649f9a393d37d3e042f4e/amazon-aurora-design-considerations-for-high-throughput-cloud-native-relational-databases.pdf)
- [https://gyazo.com/239503243de55340269b78ecc29c41ce](https://gyazo.com/239503243de55340269b78ecc29c41ce)
- (地球規模の) の部分を満たしていないのでNewSQLではない?
- 3AZに2ノードずつ分散配置
- グローバルロケーションは選択可能
- 1つのプライマリAWSリージョンと最大5つの読み取り専用セカンダリAWSリージョン
- クロスリージョンフェイルオーバーが可能
- 書き込みのスケーラビリティがないのでは?
- Aurora Multi-Masterはあるが、かなり制約が厳しい
- MySQL5.6コンパチのみ
- >通常、単一クエリのパフォーマンスは、同等のシングルマスタークラスタのパフォーマンスよりも低くなります。
- >Aurora マルチマスタークラスターは、継続的な可用性のユースケースに非常に特化しています。
- [https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-multi-master.html](https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-multi-master.html)
- MySQL/PostgreSQLの顔をしているが、裏側にはEBS/S3/DynamoDB/Route53/SWF(?)がある
閑話休題2: RDB on k8s
- プロプライエタリなSpannerではなく、MySQLやPostgreSQLを可用性高く使いたい
- [MOCO - Kubernetes 用 MySQL クラスタ運用ソフトウェア](https://blog.cybozu.io/entry/moco)
Next?
- [https://planetscale.com/blog/nonesql-all-the-devex](https://planetscale.com/blog/nonesql-all-the-devex)
- Developer Experienceの高いDBとはどんなものか?
- スキーマのバージョン管理
- アプリケーションと同じようにDBのスキーマがGitライクにバージョン管理される
- カジュアルにDDLを変更できることで、アプリケーションの開発ワークフローと同様にスキーマ変更ができる
- 複数の開発を並行で実施することを許容できる?
- 自動チューニング
- index付与のリコメンデーション
- スパイクアクセスに対応できるAutoScaling
- 自動でコスト最適化されてほしい
- なぜ?
- 事前の設計は重要だが、実装やフィードバックから得られた設計はもっと重要
- 後段で得られた知見を活かすアジャイル開発のプラクティスをRDBにも適用したい
- ドメイン知識をアプリケーションに反映し続けるDDDのプラクティスをRDBにも適用したい
- より良い名前にカラム名を変更したり、追加、削除したい
- 一方で保守コストは下げたい
- 小さなチームで小さなDBを管理する
- 開発速度を上げるために保守コストは低く保ちたい
- マイクロサービスでは大きな単一のRDBはアンチパターン
- 複数チームで一つのRDBを共有すると、チームの責任の境界が曖昧になる
- コモンズの悲劇が起きる
- 事前の設計は重要だが、実装やフィードバックから得られた設計はもっと重要
知識不足と興味不足で書けなかったこと
- Oracleの進化の歴史
- Oracle RAC
- Exadata
- Oracle cloud
- MySQL Cluster
- DB as a service
- In/On memory DB
参考
- [https://www.saiensu.co.jp/search/?isbn=978-4-7819-1390-2&y=2017](https://www.saiensu.co.jp/search/?isbn=978-4-7819-1390-2&y=2017)